
Fuzzing ImageMagick and Digging Deeper into CVE-2020-27829

Introduction:
ImageMagick is a hugely popular open source software that is used in lot of systems around the world. It is available for the Windows, Linux, MacOS platforms as well as Android and iOS. It is used for editing, creating or converting various digital image formats and supports various formats like PNG, JPEG, WEBP, TIFF, HEIC and PDF, among others.
Google OSS Fuzz and other threat researchers have made ImageMagick the frequent focus of fuzzing, an extremely popular technique used by security researchers to discover potential zero-day vulnerabilities in open, as well as closed source software. This research has resulted in various vulnerability discoveries that must be addressed on a regular basis by its maintainers. Despite the efforts of many to expose such vulnerabilities, recent fuzzing research from McAfee has exposed new vulnerabilities involving processing of multiple image formats, in various open source and closed source software and libraries including ImageMagick and Windows GDI+.
Fuzzing ImageMagick:
Fuzzing open source libraries has been covered in a detailed blog “Vulnerability Discovery in Open Source Libraries Part 1: Tools of the Trade” last year. Fuzzing ImageMagick is very well documented, so we will be quickly covering the process in this blog post and will focus on the root cause analysis of the issue we have found.
Compiling ImageMagick with AFL:
ImageMagick has lot of configuration options which we can see by running following command:
| $./configure –help |
We can customize various parameters as per our needs. To compile and install ImageMagick with AFL for our case, we can use following commands:
| $CC=afl-gcc CXX=afl=g++ CFLAGS=”-ggdb -O0 -fsanitize=address,undefined -fno-omit-frame-pointer” LDFLAGS=”-ggdb -fsanitize=address,undefined -fno-omit-frame-pointer” ./configure
$ make -j$(nproc) $sudo make install |
This will compile and install ImageMagick with AFL instrumentation. The binary we will be fuzzing is “magick”, also known as “magick tool”. It has various options, but we will be using its image conversion feature to convert our image from one format to another.
A simple command would be include the following:
| $ magick |
This command will convert an input file to an output file format. We will be fuzzing this with AFL.
Collecting Corpus:
Before we start fuzzing, we need to have a good input corpus. One way of collecting corpus is to search on Google or GitHub. We can also use existing test corpus from various software. A good test corpus is available on the AFL site here: https://lcamtuf.coredump.cx/afl/demo/
Minimizing Corpus:
Corpus collection is one thing, but we also need to minimize the corpus. The way AFL works is that it will instrument each basic block so that it can trace the program execution path. It maintains a shared memory as a bitmap and it uses an algorithm to check new block hits. If a new block hit has been found, it will save this information to bitmap.
Now it may be possible that more than one input file from the corpus can trigger the same path, as we have collected sample files from various sources, we don’t have any information on what paths they will trigger at the runtime. If we use this corpus without removing such files, then we end up wasting time and CPU cycles. We need to avoid that.
Interestingly AFL offers a utility called “afl-cmin” which we can use to minimize our test corpus. This is a recommended thing to do before you start any fuzzing campaign. We can run this as follows:
| $afl-cmin -i -o |
This command will minimize the input corpus and will keep only those files which trigger unique paths.
Running Fuzzers:
After we have minimized corpus, we can start fuzzing. To fuzz we need to use following command:
| $afl-fuzz -i |
This will only run a single instance of AFL utilizing a single core. In case we have multicore processors, we can run multiple instances of AFL, with one Master and n number of Slaves. Where n is the available CPU cores.
To check available CPU cores, we can use this command:
| $nproc |
This will give us the number of CPU cores (depending on the system) as follows:
In this case there are eight cores. So, we can run one Master and up to seven Slaves.
To run master instances, we can use following command:
| $afl-fuzz -M Master -i |
We can run slave instances using following command:
| $afl-fuzz -S Slave1 -i $afl-fuzz -S Slave2 -i |
The same can be done for each slave. We just need to use an argument -S and can use any name like slave1, slave2, etc.
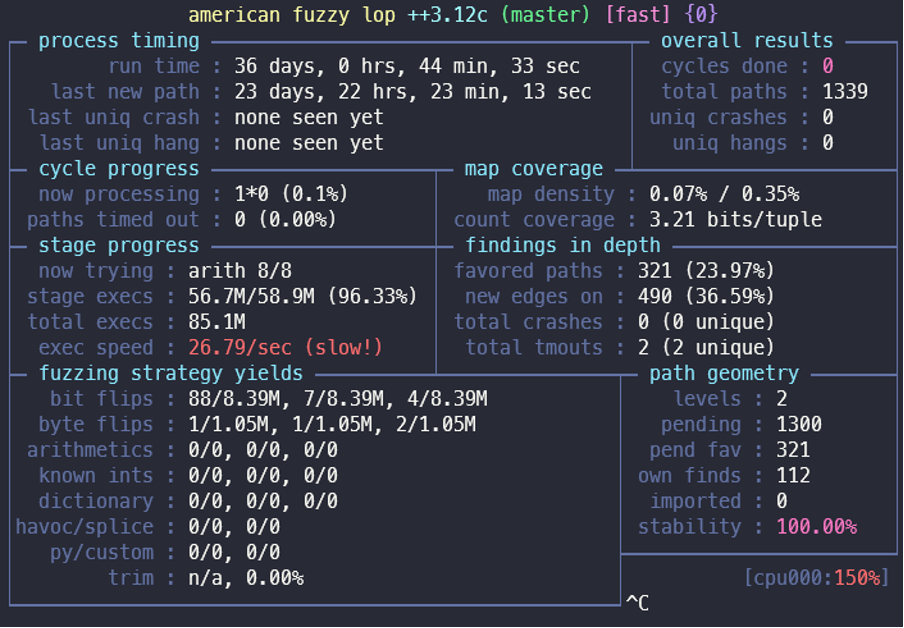
Results:
Within a few hours of beginning this Fuzzing campaign, we found one crash related to an out of bound read inside a heap memory. We have reported this issue to ImageMagick, and they were very prompt in fixing it with a patch the very next day. ImageMagick has release a new build with version: 7.0.46 to fix this issue. This issue was assigned CVE-2020-27829.
Analyzing CVE-2020-27829:
On checking the POC file, we found that it was a TIFF file.

When we open this file with ImageMagick with following command:
| $magick poc.tif /dev/null |
As a result, we see a crash like below:
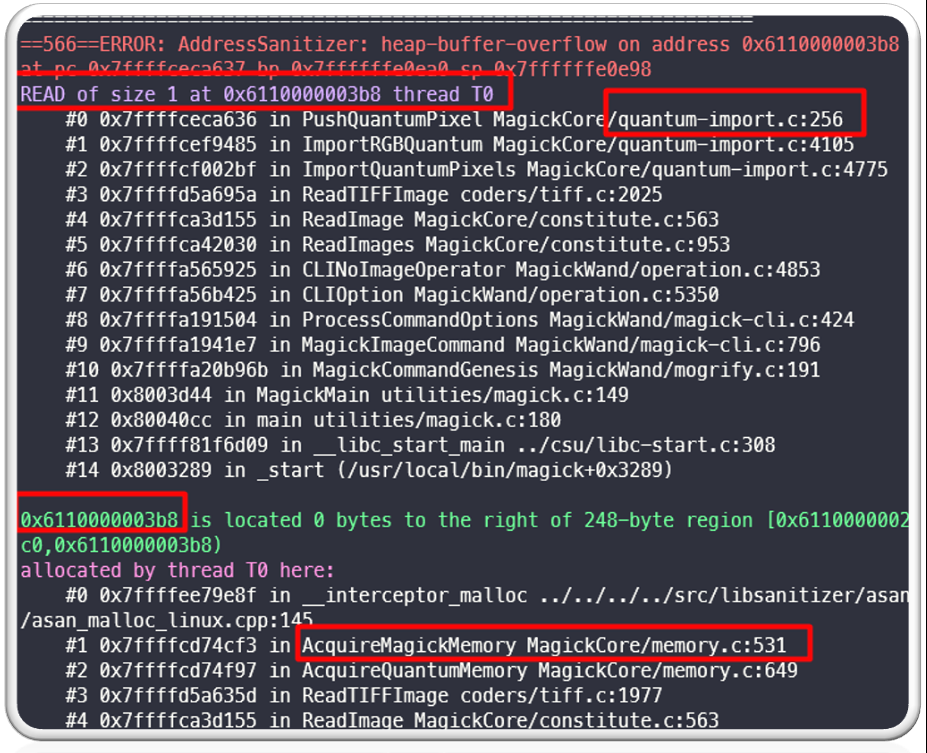
As is clear from the above log, the program was trying to read 1 byte past allocated heap buffer and therefore ASAN caused this crash. This can atleast lead to a ImageMagick crash on the systems running vulnerable version of ImageMagick.
Understanding TIFF file format:
Before we start debugging this issue to find a root cause, it is necessary to understand the TIFF file format. Its specification is very well described here: http://paulbourke.net/dataformats/tiff/tiff_summary.pdf.
In short, a TIFF file has three parts:
- Image File Header (IFH) – Contains information such as file identifier, version, offset of IFD.
- Image File Directory (IFD) – Contains information on the height, width, and depth of the image, the number of colour planes, etc. It also contains various TAGs like colormap, page number, BitPerSample, FillOrder,
- Bitmap data – Contains various image data like strips, tiles, etc.
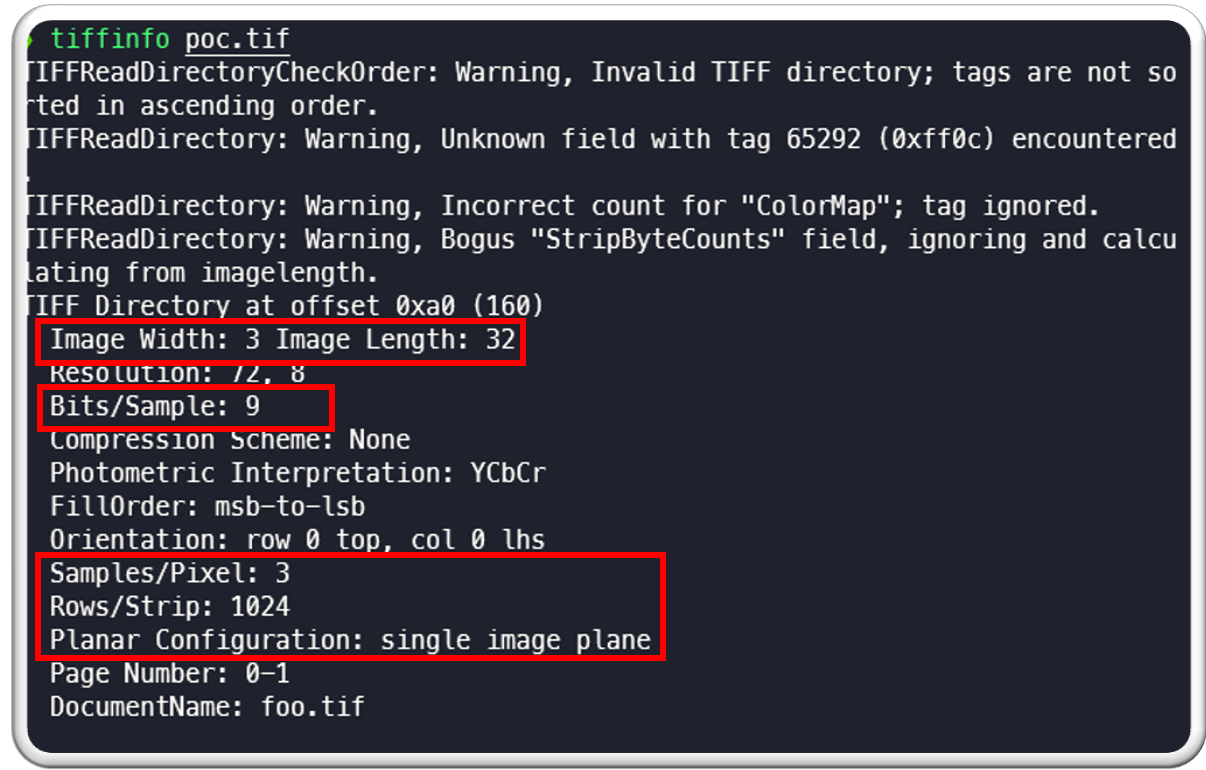
We can tiffinfo utility from libtiff to gather various information about the POC file. This allows us to see the following information with tiffinfo like width, height, sample per pixel, row per strip etc.:
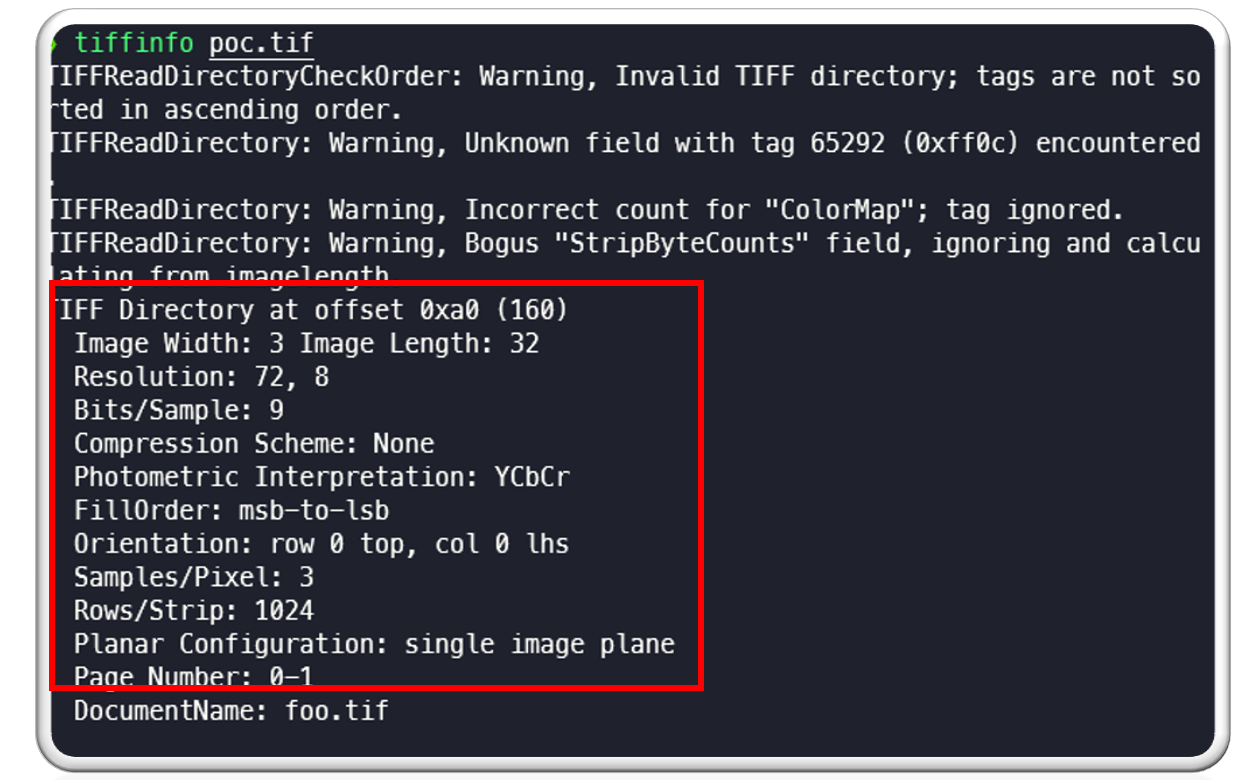
There are a few things to note here:
| TIFF Dir offset is: 0xa0
Image width is: 3 and length is: 32 Bits per sample is: 9 Sample per pixel is: 3 Rows per strip is: 1024 Planer configuration is: single image plane. We will be using this data moving forward in this post. |
Debugging the issue:
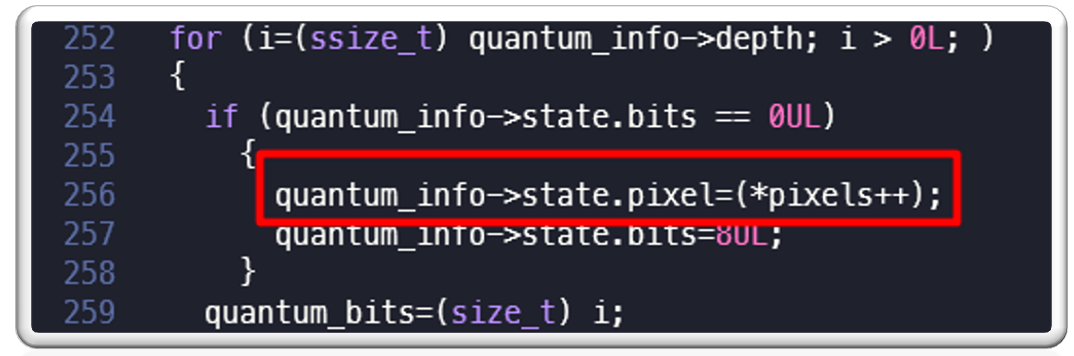
As we can see in the crash log, program was crashing at function “PushQuantumPixel” in the following location in quantum-import.c line 256:

On checking “PushQuantumPixel” function in “MagickCore/quantum-import.c” we can see the following code at line #256 where program is crashing:
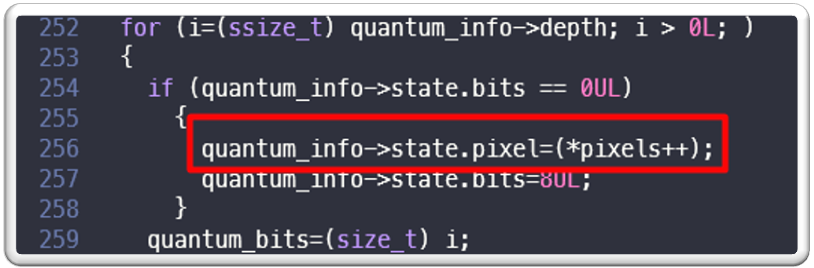
We can see following:
- “pixels” seems to be a character array
- inside a for loop its value is being read and it is being assigned to quantum_info->state.pixel
- its address is increased by one in each loop iteration
The program is crashing at this location while reading the value of “pixels” which means that value is out of bound from the allocated heap memory.
Now we need to figure out following:
- What is “pixels” and what data it contains?
- Why it is crashing?
- How this was fixed?
Finding root cause:
To start with, we can check “ReadTIFFImage” function in coders/tiff.c file and see that it allocates memory using a “AcquireQuantumMemory” function call, which appears as per the documentation mentioned here:
https://imagemagick.org/api/memory.php:
“Returns a pointer to a block of memory at least count * quantum bytes suitably aligned for any use.
The format of the “AcquireQuantumMemory” method is:
void *AcquireQuantumMemory(const size_t count,const size_t quantum)
A description of each parameter follows:
count
the number of objects to allocate contiguously.
quantum
the size (in bytes) of each object. “
In this case two parameters passed to this function are “extent” and “sizeof(*strip_pixels)”

We can see that “extent” is calculated as following in the code below:

There is a function TIFFStripSize(tiff) which returns size for a strip of data as mentioned in libtiff documentation here:
http://www.libtiff.org/man/TIFFstrip.3t.html
In our case, it returns 224 and we can also see that in the code mentioned above, “image->columns * sizeof(uint64)” is also added to extent, which results in 24 added to extent, so extent value becomes 248.
So, this extent value of 248 and sizeof(*strip_pixels) which is 1 is passed to “AcquireQuantumMemory” function and total memory of 248 bytes get allocated.
This is how memory is allocated.

“Strip_pixel” is pointer to newly allocated memory.
Note that this is 248 bytes of newly allocated memory. Since we are using ASAN, each byte will contain “0xbe” which is default for newly allocated memory by ASAN:
https://github.com/llvm-mirror/compiler-rt/blob/master/lib/asan/asan_flags.inc

The memory start location is 0x6110000002c0 and the end location is 0x6110000003b7, which is 248 bytes total.
This memory is set to 0 by a “memset” call and this is assigned to a variable “p”, as mentioned in below image. Please also note that “p” will be used as a pointer to traverse this memory location going forward in the program:
Later on we see that there is a call to “TIFFReadEncodedPixels” which reads strip data from TIFF file and stores it into newly allocated buffer “strip_pixels” of 248 bytes (documentation here: http://www.libtiff.org/man/TIFFReadEncodedStrip.3t.html):
To understand what this TIFF file data is, we need to again refer to TIFF file structure. We can see that there is a tag called “StripOffsets” and its value is 8, which specifies the offset of strip data inside TIFF file:
We see the following when we check data at offset 8 in the TIFF file:
We see the following when we print the data in “strip_pixels” (note that it is in little endian format):
So “strip_pixels” is the actual data from the TIFF file from offset 8. This will be traversed through pointer “p”.
Inside “ReadTIFFImage” function there are two nested for loops.
- The first “for loop” is responsible for iterating for “samples_per_pixel” time which is 3.
- The second “for loop” is responsible for iterating the pixel data for “image->rows” times, which is 32. This second loop will be executed for 32 times or number of rows in the image irrespective of allocated buffer size .
- Inside this second for loop, we can see something like this:

- We can notice that “ImportQuantumPixel” function uses the “p” pointer to read the data from “strip_pixels” and after each call to “ImportQuantumPixel”, value of “p” will be increased by “stride”.

Here “stride” is calculated by calling function “TIFFVStripSize()” function which as per documentation returns the number of bytes in a strip with nrows rows of data. In this case it is 14. So, every time pointer “p” is incremented by “14” or “0xE” inside the second for loop.

If we print the image structure which is passed to “ImportQuantumPixels” function as parameter, we can see following:
Here we can notice that the columns value is 3, the rows value is 32 and depth is 9. If we check in the POC TIFF file, this has been taken from ImageWidth and ImageLength and BitsPerSample value:
Ultimately, control reaches to “ImportRGBQuantum” and then to the “PushQuantumPixel” function and one of the arguments to this function is the pixels data which is pointed by “p”. Remember that this points to the memory address which was previously allocated using the “AcquireQuantumMemory” function, and that its length is 248 byte and every time value of “p” is increased by 14.
The “PushQuantumPixel” function is used to read pixel data from “p” into the internal pixel data storage of ImageMagick. There is a for loop which is responsible for reading data from the provided pixels array of 248 bytes into a structure “quantum_Info”. This loop reads data from pixels incrementally and saves it in the “quantum_info->state.pixels” field.
The root cause here is that there are no proper bounds checks and the program tries to read data beyond the allocated buffer size on the heap, while reading the strip data inside a for loop.
This causes a crash in ImageMagick as we can see below:
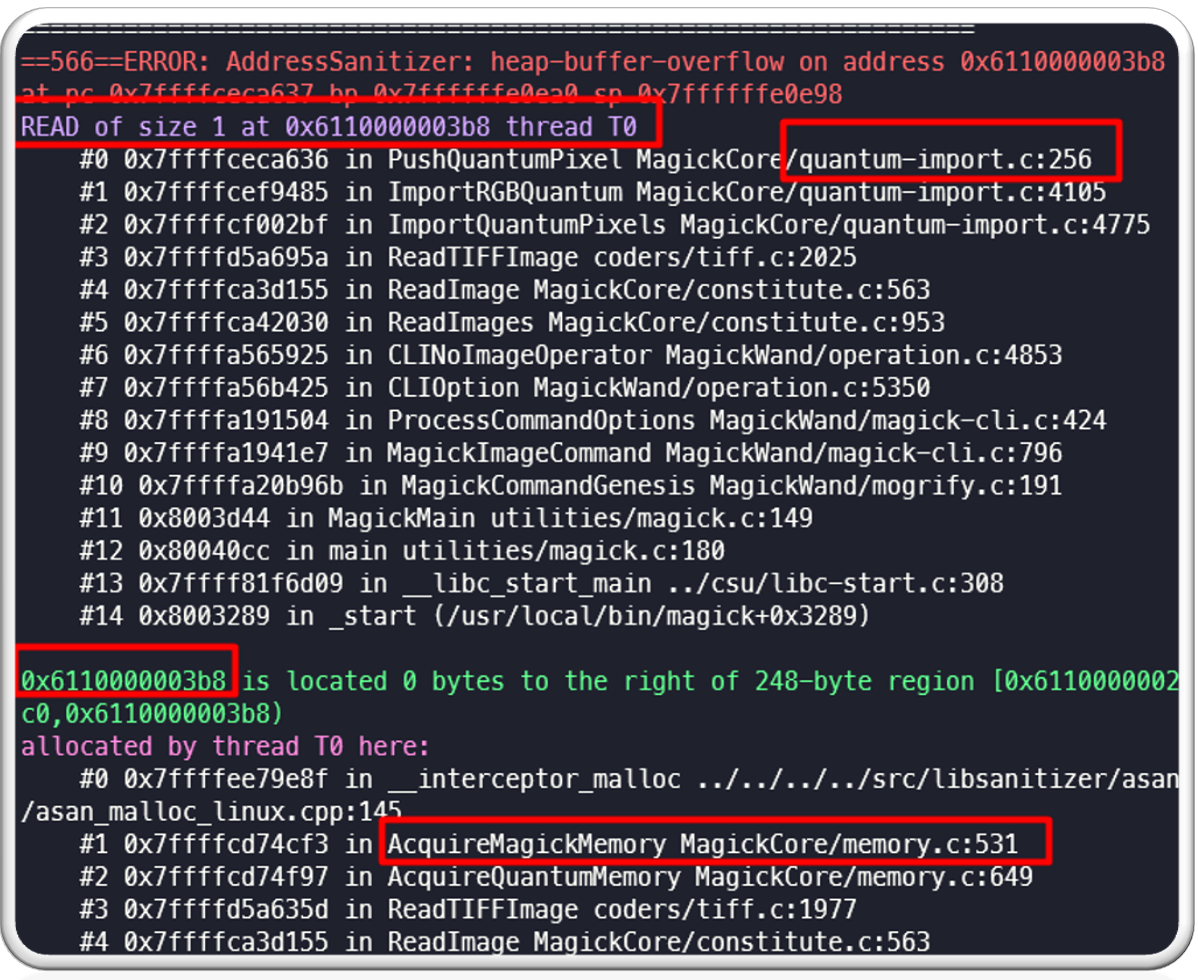
Root cause
Therefore, to summarize, the program crashes because:
- The program allocates 248 bytes of memory to process strip data for image, a pointer “p” points to this memory.
- Inside a for loop this pointer is increased by “14” or “0xE” for number of rows in the image, which in this case is 32.
- Based on this calculation, 32*14=448 bytes or more amount of memory is required but only 248 in actual memory were allocated.
- The program tries to read data assuming total memory is of 448+ bytes, but the fact that only 248 bytes are available causes an Out of Bound memory read issue.
How it was fixed?
If we check at the patch diff, we can see that the following changes were made to fix this issue:

Here the 2nd argument to “AcquireQuantumMemory” is multiplied by 2 thus increasing the total amount of memory and preventing this Out of Bound read issue from heap memory. The total memory allocated is 496 bytes, 248*2=496 bytes, as we can see below:

Another issue with the fix:
A new version of ImageMagick 7.0.46 was released to fix this issue. While the patch fixes the memory allocation issue, if we check the code below, we can see that there was a call to memset which didn’t set the proper memory size to zero.

Memory was allocated extent*2*sizeof(*strip_pixels) but in this memset to 0 was only done for extent*sizeof(*strip_pixels). This means half of the memory was set to 0 and rest contained 0xbebebebe, which is by default for ASAN new memory allocation.

This has since been fixed in subsequent releases of ImageMagick by using extent=2*TIFFStripSize(tiff); in the following patch:
Conclusion:
Processing various image files requires deep understanding of various file formats and thus it is possible that something may not be exactly implemented or missed. This can lead to various vulnerabilities in such image processing software. Some of this vulnerability can lead to DoS and some can lead to remote code execution affecting every installation of such popular software.
Fuzzing plays an important role in finding vulnerabilities often missed by developers and during testing. We at McAfee constantly fuzz various closed source as well as open source software to help secure them. We work very closely with various vendors and do responsible disclosure. This shows McAfee’s commitment towards securing the software and protecting our customers from various threats.
We will continue to fuzz various software and work with vendors to help mitigate risk arriving from such threats.
We would like to thank and appreciate ImageMagick team for quickly resolving this issue within 24 hours and releasing a new version to fix this issue.
The post Fuzzing ImageMagick and Digging Deeper into CVE-2020-27829 appeared first on McAfee Blogs.